Parquet形式のデータは列ベースのデータフォーマットで、Apacheプロジェクトの一つです。商用サービスだとDatabricksが有名ですね。
Parquet形式の利点は行ベースのデータ形式(csvとか)と比べて、特定の列データだけを扱うクエリが非常に高速になることです。また、効率的なデータ圧縮により容量も小さく済みます。
まずは事始めとして、国税庁の法人データをcsvで取得して、それをParquet形式に変換してみました。
コード:
csvをParquet形式データに変換するコードは下記です。
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
# ダウンロードしたcsvを読み込む
df = pd.read_csv('./00_zenkoku_all_20230428.csv', encoding="utf-8")
table = pa.Table.from_pandas(df)
# Parquet形式データに変換する
pq.write_table(table, './00_zenkoku_all_20230428.parquet')
Parquet形式データをpandasのデータフレームに展開して中身を確認してみます
import pyarrow.parquet as pq
table = pq.read_table("./00_zenkoku_all_20230428.parquet")
df = table.to_pandas()
df.info()
結果:
以下のように成功しました。約530万件(5307284件)のデータとなりました。メモリは1.2GBも使っています。データのファイルサイズは、csv形式が1.04 GBだったのに対して、 Parquet形式データは275 MBとかなり小さくなりました。
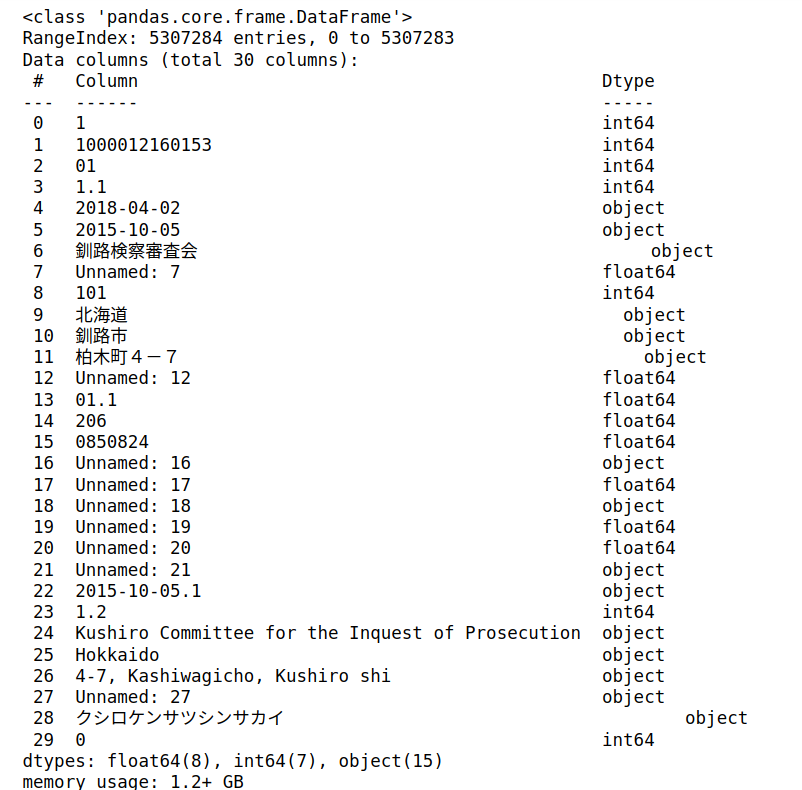
カラム名がデータの一行目になっているのが変ですね。ちゃんと扱うには、別途xml形式のダウンロードデータもあるので、そこからカラム名を取り出して別定義するなどの手間が必要です。ということで、カラム名を定義したものがこちら。
コード:
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
# カラム名を定義
column_names = ['sequenceNumber', 'corporateNumber', 'process', 'correct', 'updateDate', 'changeDate', 'name', 'nameImageId', 'kind', 'prefectureName', 'cityName', 'streetNumber', 'addressImageId', 'prefectureCode', 'cityCode', 'postCode', 'addressOutside', 'addressOutsideImageId', 'closeDate', 'closeCause', 'successorCorporateNumber', 'changeCause', 'assignmentDate', 'latest', 'enName', 'enPrefectureName', 'enCityName', 'enAddressOutside', 'furigana', 'hihyoji']
# CSVデータを読み込む
df = pd.read_csv('./00_zenkoku_all_20230428.csv', encoding="utf-8", names=column_names)
table = pa.Table.from_pandas(df)
# Parquet形式データに変換する
pq.write_table(table, './00_zenkoku_all_20230428.parquet')
結果:
別途、xmlデータのタグ名から取り出したカラム名の候補と、csvの実データをスプレッドシート上で並べて、ズレがないかを目視確認したのち、カラム名をコード中にセットして、成功しました。以下のようにカラムがきちんとセットされて、奇麗なデータフレームになりました。
