ChatGPTで、マトリックスに出てくる縦スクロール・アニメを作るjsコードを書いてもらいました。
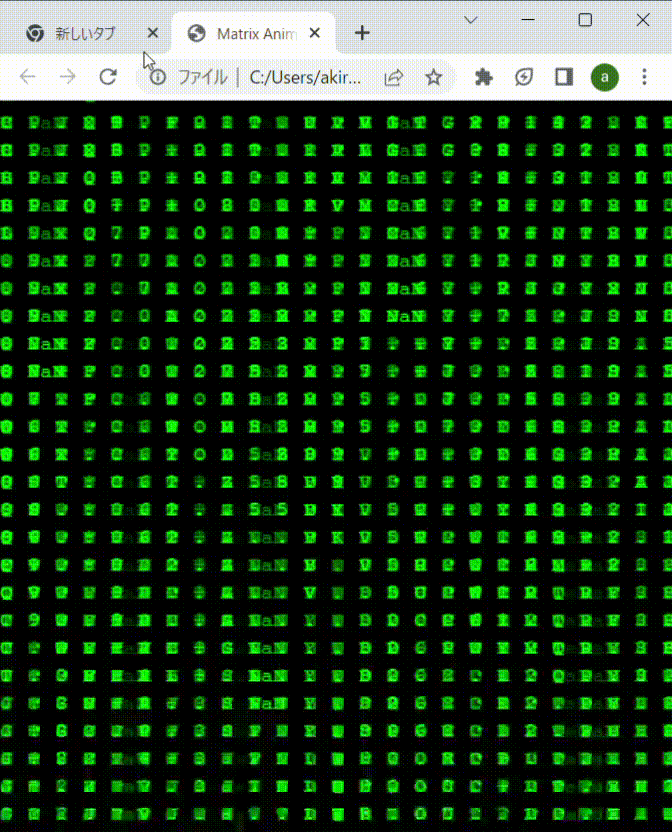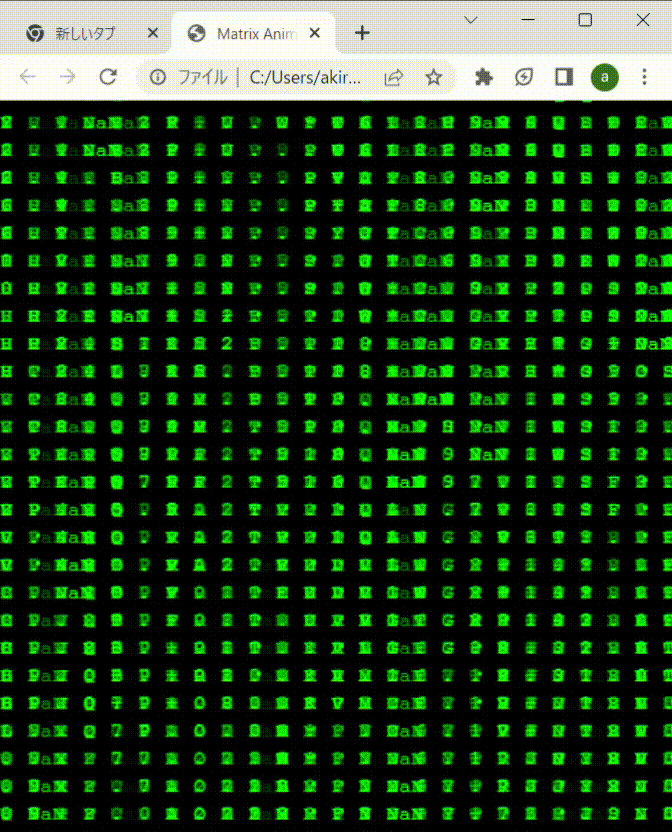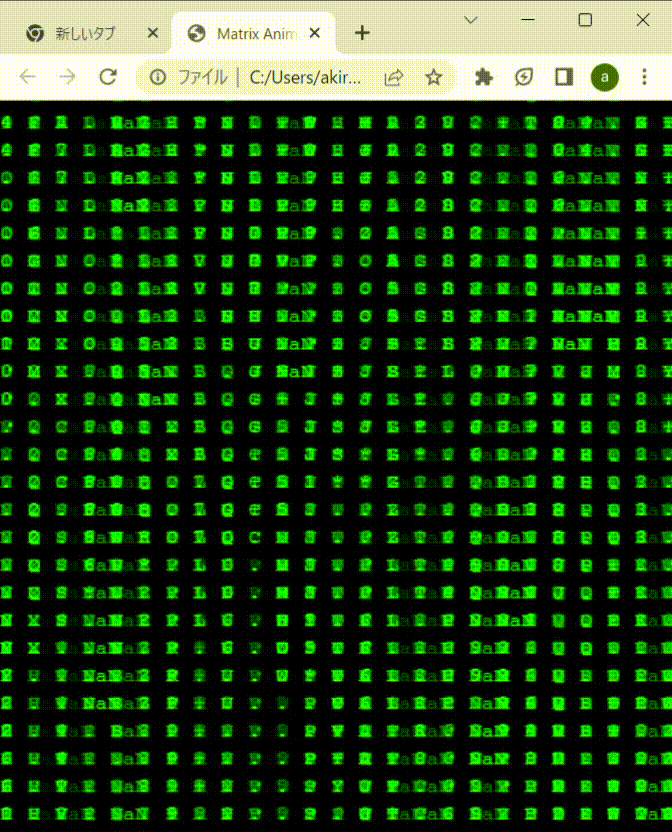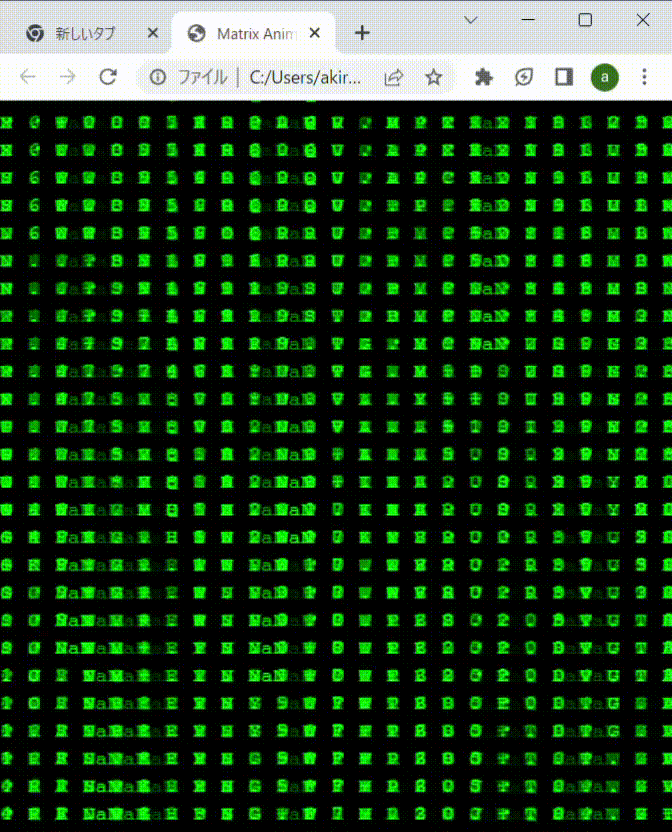
先に結果から。下記のように成功しました。表示する要素に指定する文字は、0-9,A-Zだけだと変化が乏しいので、記号や空白も混ぜて調整してます。記号とか漢字も混ぜると、より、それっぽくなるかも。
指示文(プロンプト):
映画マトリックスに出てくる、文字が上から下に縦スクロールしていくアニメーションを表示するjsプログラムを書いてください。HTMLの <canvas> 要素を使用してください。
回答:
- 以下は、JavaScriptを使用して、マトリックスのように上から下に縦に流れる文字列アニメーションを表示する方法の例です。
- このスクリプトは、ランダムに選択した文字列の配列から文字を選択し、指定された文字列の長さのマトリックスを初期化します。
- それから、一定の間隔で、各行に対して文字列を表示し、配列の先頭に新しいランダムな文字を追加し、配列の最後から文字を削除して、アニメーションを作成します。
- HTMLの canvas 要素を使用して、同じアニメーションを作成します。文字列を表示するために fillText() を使用し、キャンバスの背景を透過させるために fillRect() を使用しています。
- また、CSSで canvas 要素をスタイル設定しています。
<!DOCTYPE html>
<html>
<head>
<title>Matrix Animation</title>
<style>
body {
background-color: black;
margin: 0;
padding: 0;
overflow: hidden;
}
canvas {
display: block;
}
</style>
</head>
<body>
<canvas id="canvas"></canvas>
<script>
// canvas要素を取得
var canvas = document.getElementById("canvas");
// canvasの大きさを設定
canvas.width = window.innerWidth;
canvas.height = window.innerHeight;
// canvasの描画コンテキストを取得
var ctx = canvas.getContext("2d");
// 文字列の配列
var chars = [" "," "," "," "," "," "," "," "," "," "," "," "," ",".",".",".",".",".",".",".",".",".",".",".",".",".",".",".",".",".",".",".",".",".","・","・","・","・","・","+","+","*","."*".",".",".",".",".",".",".",".",".",".",".",".",".",".",".",".",".",".","0","1","2","3","4","5","6","7","8","9","A","B","C","D","E","F","G","H","I","J","K","L","M","N","O","P","Q","R","S","T","U","V","W","X","Y","Z"];
// 文字列をランダムに選択
function randomChar() {
return chars[Math.floor(Math.random() * chars.length)];
}
// 文字列の長さ
var length = 100;
// 初期化
var matrix = [];
for (var i = 0; i < length; i++) {
matrix[i] = [];
for (var j = 0; j < window.innerHeight / 20; j++) {
matrix[i][j] = randomChar();
}
}
// 文字列を表示
function draw() {
ctx.fillStyle = "rgba(0, 0, 0, 0.1)";
ctx.fillRect(0, 0, canvas.width, canvas.height);
ctx.fillStyle = "#0F0"; // 文字の色
ctx.font = "15px Courier"; // フォント
for (var i = 0; i < length; i++) {
var row = matrix[i];
for (var j = 0; j < row.length; j++) {
var char = row[j];
ctx.fillText(char, i * 20, j * 20);
}
matrix[i].unshift(randomChar());
matrix[i].pop();
}
}
// 一定間隔でアニメーションを表示
setInterval(draw, 100);
</script>
</body>
</html>










