日本の住所表記がヤバすぎる、という記事から
「日本の住所のヤバさ」知れ渡る 正規化・名寄せ問題、Twitterトレンドに - ITmedia NEWS
こちらの記事も見ていて
日本の住所の正規化に本気で取り組んでみたら大変すぎて鼻血が出た。 - Qiita
ちょっと興味がわいたので、
からcsvデータをダウンロードして、いじってみました。
ダウンロードしたcsvデータの文字化け
ダウンロードした各県のデータ(zip)を解凍し、
find /path/to/folder -name "*.zip" -exec unzip {} -d /path/to/folder \;
中身のcsvを取り出して、
find /path/to/folder -type f -name "*.csv" -exec mv {} /path/to/new/folder \;
下記のようにマージしたところ、
cat /path/to/folder/*.csv > merged.csv
このcsvをpandasに入れる前に躓きました。
お約束で文字コードの不具合。cp932でも読み取れないデータあり、このままだとエラーでpandasに入りません。

ちなみに、単純にマージしたcsvで件数は19627711行となっていたので、日本には約2000万の地点(国土地理院のデータベースにある数として)があることになります。
csvデータで1.88GBと、なかなかのサイズ(手元のパソコンで扱うにはちょっと重いな)
あと、他にも気付いた点として、福岡県のcsvデータが崩れていました(データが「代表フラグ」から始まっている)。


csvデータをnkfでcp932からutf-8に変換してpandasに取り込むまで
解凍されたcsvデータはcp932でも、ところどころ文字化けしていたので、まずはpandasのデフォであるutf-8に変換します。
pythonのライブラリで何とかできないものかと、この辺の記事を見ながら、いろいろトライしていたけどエラー(UnicodeDecodeError: 'shift_jis' codec can't decode byte 0xed in position 154548: illegal multibyte sequence とか)でうまくいかなかったので、「nkf」というライブラリを使ったところ、コマンドラインだけで解決しました。
以下、手順。
1. nkfをインストール。Ubuntuの場合。windows版もあるそうです。
sudo apt-get install nkf2. CP932からUTF-8に変換する場合は、以下のコマンドを実行。
nkf -w --cp932 変換前のファイル名 > 変換後のファイル名
3. 正常にpandasに取り込めるか確認。
以下のように読み込めました。確認用に島根県のcsvデータだけを入れてます。
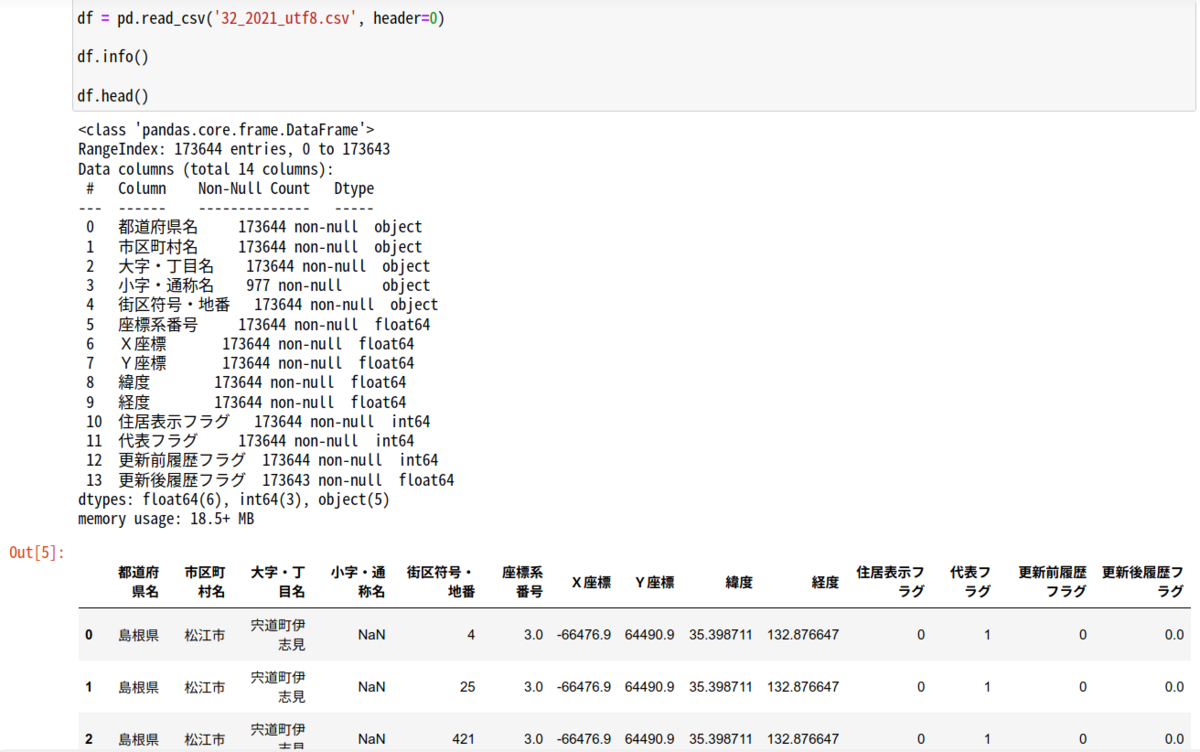
あとはカラムがずれている福岡県のデータだけは、別途、カラムを入れ替えてデータを奇麗にすれば良いですね。